
|
|
Целые числа
Данные каким-либо образом необходимо представлять в памяти компьютера. Существует множество различных типов данных, простых и довольно сложных, имеющих большое число компонентов и свойств. Однако, для компьютера необходимо использовать некий унифицированный способ представления данных, некоторые элементарные составляющие, с помощью которых можно представить данные абсолютно любых типов. Этими составляющими являются числа, а вернее, цифры, из которых они состоят. С помощью цифр можно закодировать практически любую дискретную информацию. Поэтому такая информация часто называется цифровой (в отличие от аналоговой, непрерывной).
Первым делом необходимо выбрать систему счисления, наиболее подходящую для применения в конкретных устройствах. Для электронных устройств самой простой реализацией является двоичная система: есть ток - нет тока, или малый уровень тока - большой уровень тока. Хотя наиболее эффективной являлась бы троичная система. Наверное, выбор двоичной системы связан еще и с использование перфокарт, в которых она проявляется в виде наличия или отсутствия отверстия. Отсюда в качестве цифр для представления информации используются 0 и 1.
Таким образом данные в компьютере представляются в виде потока нулей и единиц. Один разряд этого потока называется битом. Однако в таком виде неудобно оперировать с данными вручную. Стандартом стало разделение всего потока на равные последовательные группы из 8 битов - байты или октеты. Далее несколько байтов могут составлять слово. Здесь следует разделять машинное слово и слово как тип данных. В первом случае его разрядность обычно равна разрядности процессора, т.к. машинное слово является наиболее эффективным элементом для его работы. В случае, когда слово трактуется как тип данных (word), его разрядность всегда равна 16 битам (два последовательных байта). Также как типы данных существую двойные слова (double word, dword, 32 бита), четверные слова (quad word, qword, 64 бита) и т.п.
Теперь мы вплотную подошли к представлению целых чисел в памяти. Т.к. у нас есть байты и различные слова, то можно создать целочисленные типы данных, которые будут соответствовать этим элементарным элементам: byte (8 бит), word (16 бит), dword (32 бита), qword (64 бита) и т.д. При этом любое число этих типов имеет обычное двоичное представление, дополненное нулями до соответствующей размерности. Можно заметить, что число меньшей размерности можно легко представить в виде числа большей размерности, дополнив его нулями, однако в обратном случае это не верно. Поэтому для представления числа большей размерности необходимо использовать несколько чисел меньшей размерности. Например:
- qword (64 бита) можно представить в виде 2 dword (32 бита) или 4 word (16 бит) или 8 byte (8 бит);
- dword (32 бита) можно представить в виде 2 word (16 бит) или 4 byte (8 бит);
- word (16 бит) можно представить в виде 2 byte (8 бит);
Если A - число, B1..Bk - части числа, N - разрядность числа, M - разрядность части, N = k*M, то:
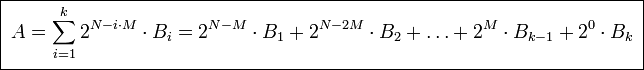
Например:
- A = F1E2D3C4B5A69788 (qword)
- A = 232 * F1E2D3C4 (dword) + 20 * B5A69788 (dword)
- A = 248 * F1E2 (word) + 232 * D3C4 (word) + 216 * B5A6 (word) + 20 * 9788 (word)
- A = 256 * F1 (byte) + 248 * E2 (byte) + ... + 28 * 97 (byte) + 20 * 88 (byte)
Существуют понятия младшая часть (low) и старшая часть (hi) числа. Старшая часть входит в число с коэффициентом 2N-M, а младшая с коэффициентом 20. Например:
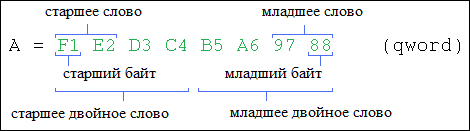
Байты числа можно хранить в памяти в различном порядке. В настоящее время используются два способа расположения: в прямом порядке байт и в обратном порядке байт. В первом случае старший байт записывается в начале, затем последовательно записываются остальные байты, вплоть до младшего. Такой способ используется в процессорах Motorola и SPARC. Во втором случае, наоборот, сначала записывает младший байт, а затем последовательно остальные байты, вплоть до старшего. Такой способ используется в процессорах архитектуры x86 и x64. Далее приведен пример:

Используя подобные целочисленные типы можно представить большое количество неотрицательных чисел: от 0 до 2N-1, где N - разрядность типа. Однако, целочисленный тип подразумевает представление также и отрицательных чисел. Можно ввести отдельные типы для отрицательных чисел от -2N до -1, но тогда такие типы потеряют универсальность хранить и неотрицательные, и отрицательные числа. Поэтому для определения знака числа можно выделить один бит из двоичного представления. По соглашению, это старший бит. Остальная часть числа называется мантиссой.
Если старший бит равен нулю, то мантисса есть обычное представление числа от 0 до 2N-1-1. Если же старший бит равен 1, то число является отрицательным и мантисса представляет собой так называемый дополнительный код числа. Поясним на примере:
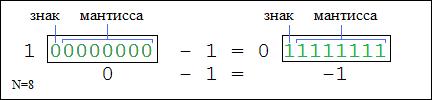
Как видно из рисунка, дополнительный код равен разнице между числом 2N-1 и модулем исходного отрицательного числа (127 (1111111) = 128 (10000000) - |-1| (0000001)). Из этого вытекает, что сумма основного и дополнительного кода одного и того же числа равна 2N-1.
Из вышеописанного получается, что можно использовать только целочисленные типы со знаком для описания чисел. Однако существует множество сущностей, которые не требуют отрицательных значений, а значит, место под знак можно включить в представление неотрицательного числа, удвоив количество различных неотрицательных значений. Как результат, в современных компьютерах используются как типы со знаком или знаковые типы, так и типы без знака или беззнаковые типы.
В итоге можно составить таблицу наиболее используемых целочисленных типов данных:
| Общее название | Название в Pascal | Название в C++ | Описание | Диапазон значений |
| unsigned byte | byte | unsigned char | беззнаковый 8 бит | 0..255 |
| signed byte | shortint | char | знаковый 8 бит | -128..127 |
| unsigned word | word | unsigned short | беззнаковый 16 бит | 0..65535 |
| signed word | smallint | short | знаковый 16 бит | -32768..32767 |
| unsigned double word | cardinal | unsigned int | беззнаковый 32 бита | 0..232-1 |
| signed double word | integer | int | знаковый 32 бита | -231..231-1 |
| unsigned quad word | uint64 | unsigned long long unsigned __int64_t (VC++) | беззнаковый 64 бита | 0..264-1 |
| signed quad word | int64 | long long __int64_t (VC++) | знаковый 64 бита | -263..263-1 |